Classyfy CS 175: Project in AI (in Minecraft with Project Malmo)
Embedding wasn’t possible so click on the image below to see the gameplay of our agent.

layout: default title: Status —
Status
Project Summary
We changed our project from object detection to classification utilizng the Inception v3 network provided on TensorFlow. This allowed us to build classifiers using a small amount of data. The classifier runs in the background of Malmo and outputs the names of objects detected on screen in the chatbox. We achieved fairly good accuracy albeit only on the two trained objects. This is quite close to the ideal performance we envisioned. Our next steps will be to further improve accuracy and increase detectable classes of objects.
Approach
Inception v3, as a neural network model, is made up of layers of nodes stacked on top of each other. However, only the last layer before the final output layer, also called the bottleneck layer, will change for the specific object that we want to classify. Every other layer will contain information that are generally good for classifying most images. Therefore, we left all previous layers in already-trained state to speed up our training process. Since the inception model is already included in the TensorFlow library, we only needed the script to retrain the model for our purposes. The TensorFlow For Poets tutorial (https://codelabs.developers.google.com/codelabs/tensorflow-for-poets/#4) provides the completed version of this script, obtainable here:
https://raw.githubusercontent.com/tensorflow/tensorflow/r1.1/tensorflow/examples/image_retraining/retrain.py
With the trainer in hand, we began our data collection process. For each object we wanted to train, we generate the same object in different worlds that guarantee overall different lighting and visibility on the object to diversify training data. We use a simple command
call(["screencapture", "./images/" + "apple" + str(i) + ".png"])
to capture a screenshot every second. With this method, we generated roughly 40 images for each object. We started the actual training process by running the retrain.py script as follows
python retrain.py \
--bottleneck_dir=bottlenecks \
--how_many_training_steps=500 \
--model_dir=inception \
--summaries_dir=training_summaries/basic \
--output_graph=retrained_graph.pb \
--output_labels=retrained_labels.txt \
--image_dir=minecraft_photos
The script will proceed to generate bottleneck files, as mentioned above, and begin the training of the final layer. To do so, the trainer runs repeated steps, each randomly chooses 10 images from the training set and retrieve the respective bottlenecks to form a prediction on the final layer. The results will be compared against the true labels of the images. The differences used to update the weight values of the final layer using stochastic gradient descent. Note that we limited the amount of training steps to 500 while a general image classification training on this model will usually run 4000 steps. This is due to the limited size of our training set compared to the amount of images used during normal practices. The recommended number of images for a relatively accurate classifier is 200 or more. Our collection of 40 images barely meets the minimum requirement for training a passable A.I. Since increasing training steps will only be beneficial given sufficient amount of training data, we needn’t perform the default of 4000 training steps.
Evaluation
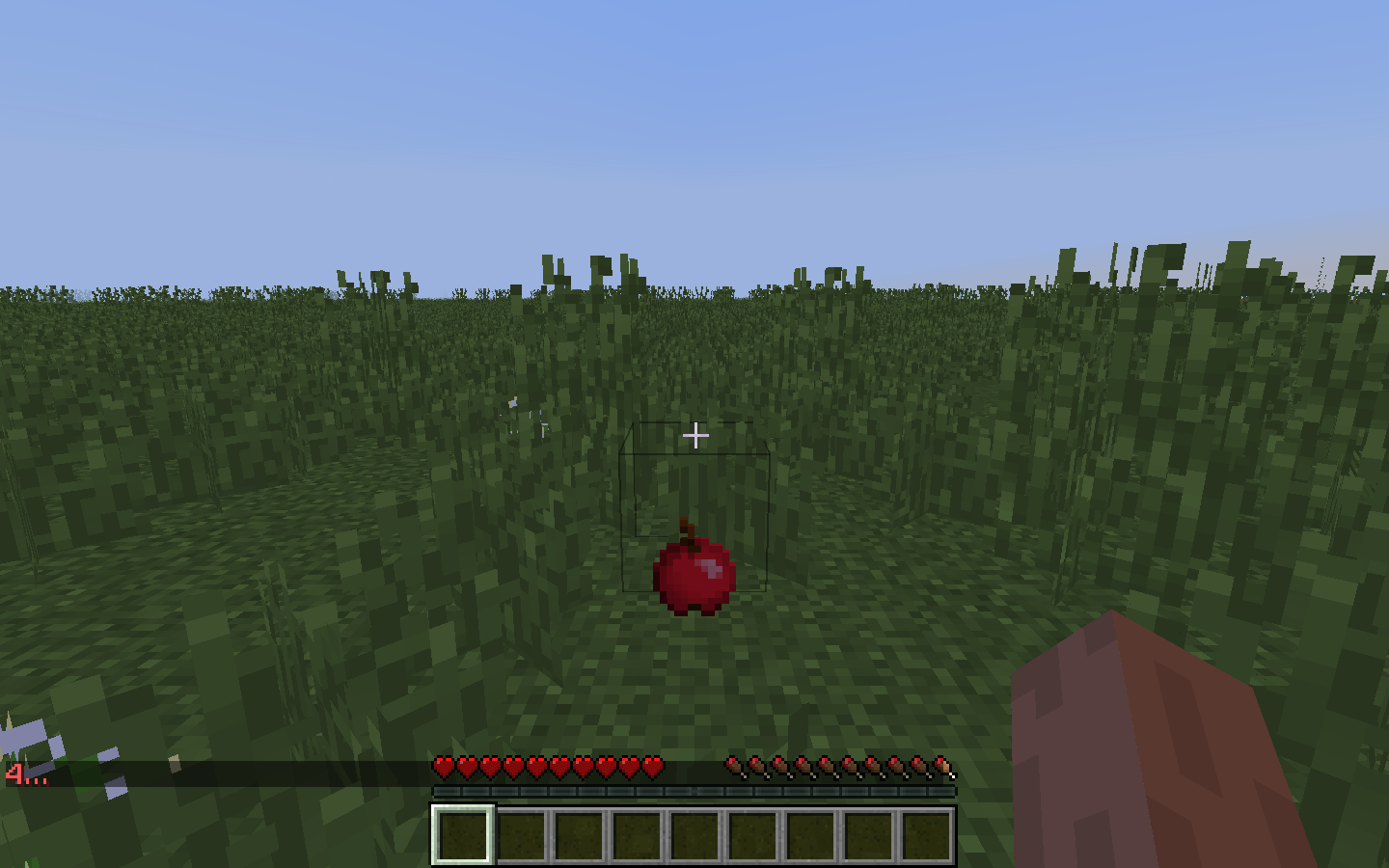
Results
apples (score = 0.99035) coal (score = 0.00965)
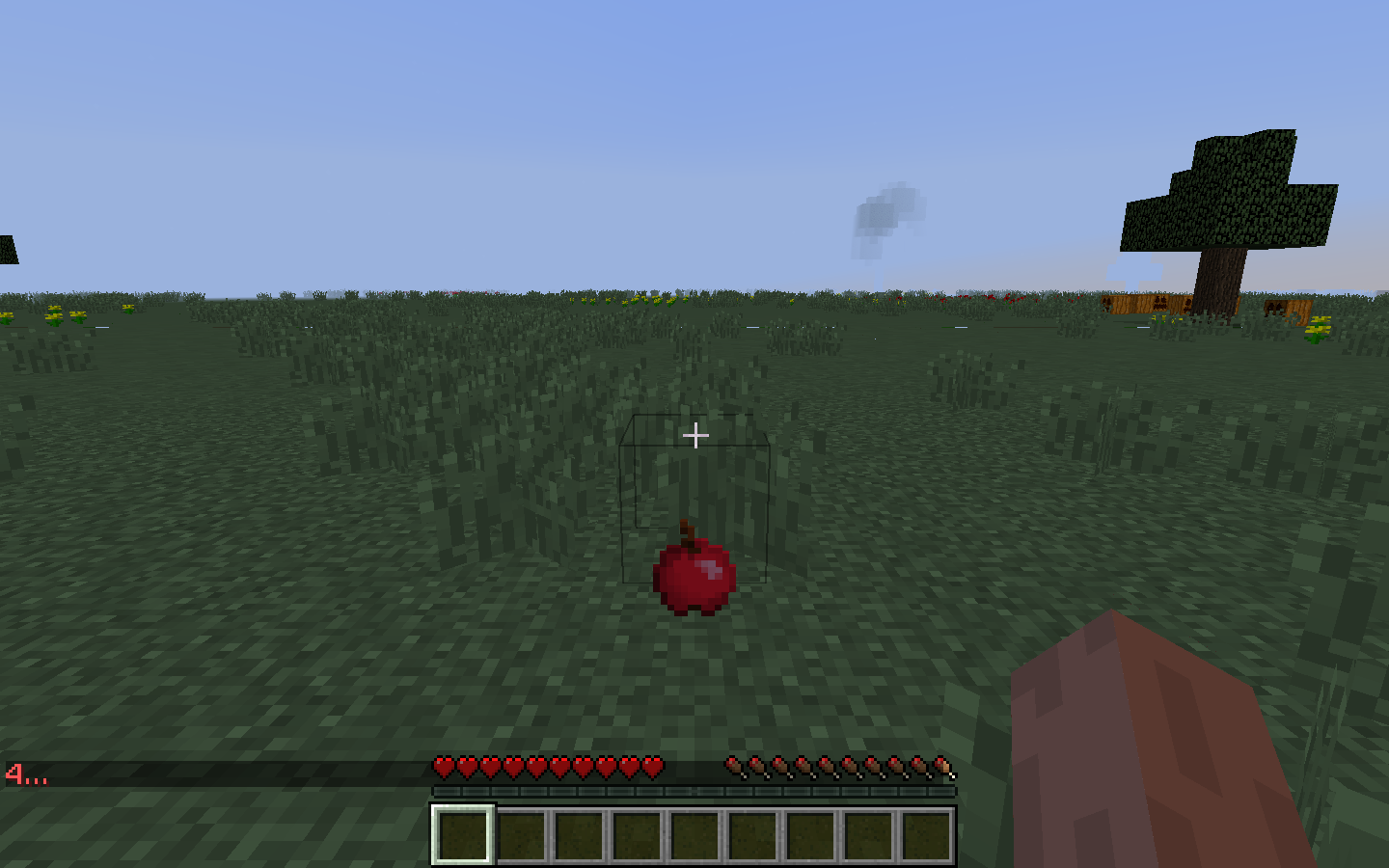
Results
apples (score = 0.97061) coal (score = 0.02939)
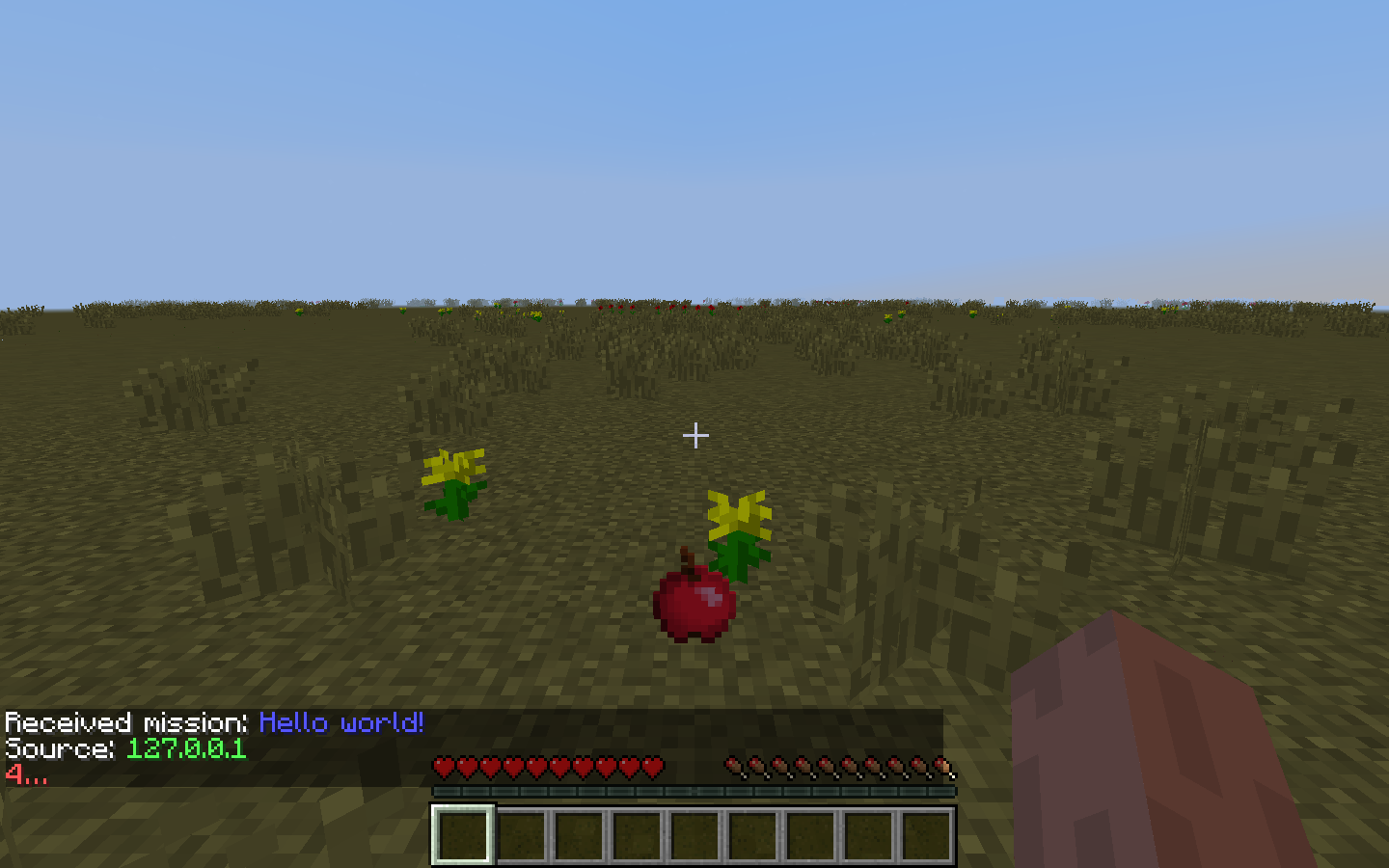
Results
apples (score = 0.97860) coal (score = 0.02140)
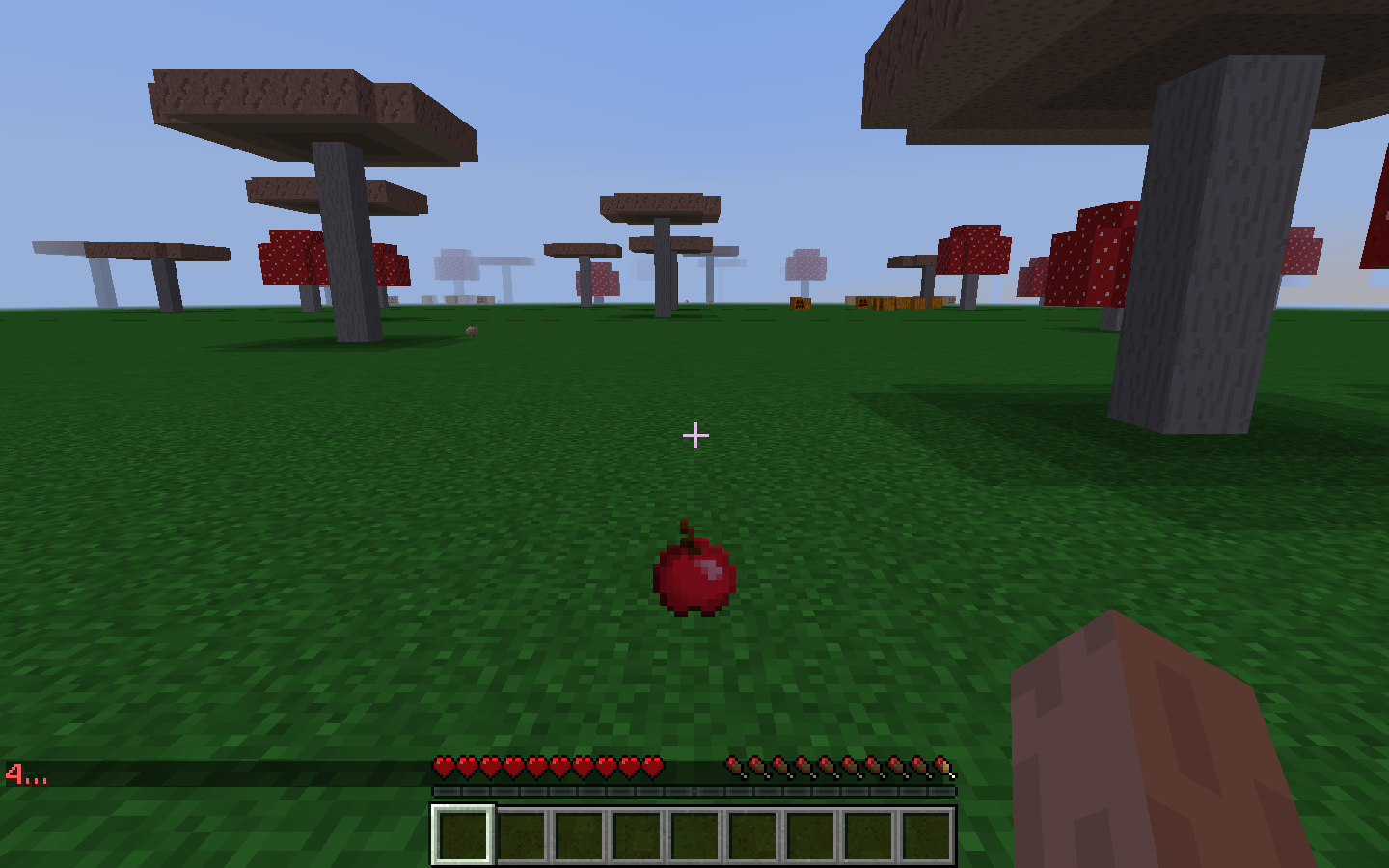
Results
apples (score = 0.80647) coal (score = 0.19353)
Results
apples (score = 0.95400) coal (score = 0.04600)
Results
apples (score = 0.99896) coal (score = 0.00104)
Results
apples (score = 0.98701) coal (score = 0.01299)
Quantitative Evaluation
For our quantitative evaluation, we used TensorFlow’s built in mathematical calculations to produce a confidence indicating whether or not the classification was successful for each image. For example, in the 7 images above, we have output below each image for the two different classes we trained our classifier on, ‘apples’ and ‘coal’. For those two classes, we have results from TensorFlow’s calculations which uses functions like the softmax function used in neural networks. This function is used in the final layer of a neural net classifier and computes probabilities which allow a confidence to be returned, leading to the classification of the object in the images above as ‘apples’ since the confidence returned in each run is above 0.80. All seven of the images above passed as each run resulted in the ‘apples’ classification which is 100% accuracy. However, this was on images very similar to our training data. In some other scenarios, our classifier doesn’t give a clear confidence reading on which item was in the image. As a result, we look forward to increasing our training data set from a mere 20 per item to 100 per item and increase the number of items. We hope to achieve better accuracy this way. Over several different runs of real time gameplay our agent had an accuracy of approximately 70% - 75%.
This is only using one Minecraft item. So for our final iteration, we would like to test it on many more of Minecraft’s 188 built-in items. We would also add more classes so it wouldn’t be a simple either-or prediction.
Further information and visualization of the softmax equation used in TensorFlow (taken from TensorFlow Documentation):
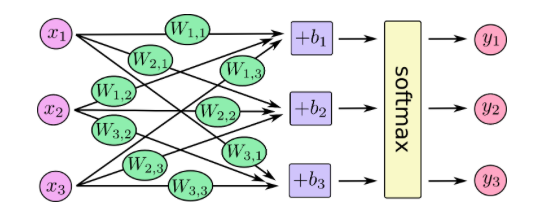


Qualitative Evaluation
For our qualitative evaluation, we wanted to make sure that we had generated a diverse set of environments for the objects we wanted to recognize. For example, in the 7 images above, we have an Apple shown in rainy, snowy, and clear weather. We also have multiple different backgrounds, including grass, trees, flowers, mushrooms, forests, and boxes. In the clear weather environments, the screen is much brighter as opposed to the screen in rainy or snowy weather. These variations helped us qualitatively evaluate our project. For each of the variations above, our classifier was able to confidently predict the correct class, ‘apples’. For future iterations, we would like to add more angles, as we only tested on straight point-of-view angles in the above images.
Remaining Goals and Challenges
While the original vision for the project revolved around object detection with precise bounding boxes indicating results, the actual execution was more challenging than we imagined. We experimented with various commonly used object recognition techniques, including HOG feature descriptors and Haar Cascade using OpenCV, but the results were far from satisfactory. We believed that the primary cause of inaccurate results were the insufficient amount of training data. A typical classifier requires thousands of positive and negative images in order to achieve acceptable results. We decided that manually collecting this amount of data and having each image properly annotated for training was not a feasable approach. This forced us to scratch all of our progress and turn to image classification using neural networks on TensorFlow instead. Getting Tensorflow to work with Malmo also caused us tremendous pain. Because of Malmo and TensorFlow linking to different versions fo Python, we had to abandon the Tensorflow package from pip and make out own build using source files, an incredibly lengthy process. Now that the project has steered away from our original vision of object detection, we are going to stick to what we have and improve on the results. Primarily, we will start broadening our training data set to around 200 images for each object. We predict that this will improve our classification accuracy to 95%+. In addition, we will increase the number of classes detectable by experimenting with more complex objects such as trees, river, and houses. We hope that by the end we will have an A.I that can pick out several objects accurately from looking at fairly complex scenes. We would also like to increase our work with object detection by stating which locations images are in or drawing bounding boxes around them. After all you can’t have true vision without both classification and detection. Finally, we will try to integrate our agent more into minecraft by having it realize what recipes can be created from the images on screen and the inventory.