Classyfy CS 175: Project in AI (in Minecraft with Project Malmo)
Video
Project Summary
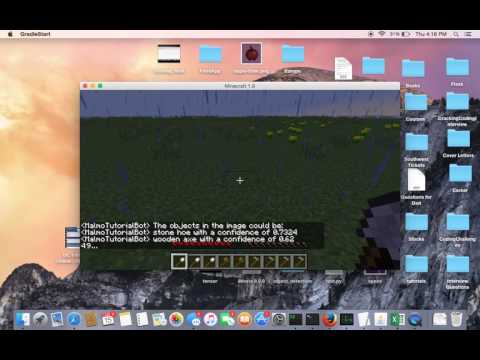
We started out with the goal of being able to implement Object Detection. This resulted in us being able to detect images close to the Agent but did not work out very well for different variations. This includes the object being a different size / distance from the Agent. As a result, we pivoted to Classification: predicting what an object is.
After changing to Classification, we focused on building classifiers using minimal training data. For our first iteration we want to create a prototype of our application: accurate classification of two minecraft items. Our final prototype is to classify multiple objects on the screen at once as the agent moves through the world. Our final prototype successfully classifies a multitude of objects (10 item classes). The classifier runs in the background of Project Malmo and outputs the detected classification result in the Project Malmo chatbox.
Since then, we have been testing the extents of our application, attempting to improve accuracy and adding capabilities: recognizing multiple objects on screen at once. Recognizing multiple objects on screen does work to an extent, but the confidence levels aren’t strong enough to consider it successful yet. We need artificial intelligence for this project to classify these objects instantaneously. It is non-trivial because of the slight changes in environments (e.g. clear vs. rain / snow), differing layouts, backgrounds, and angles that the object could reside in.
Approaches
Inception v3, as a neural network model, is made up of layers of nodes stacked on top of each other. However, thanks to transfer learning, only the last layer before the final output layer, also called the bottleneck layer, will change for the specific objects that we want to classify.
Earlier hidden layers recognize traditional image recognition approaches such as feature extraction: edges, colors, shapes, gaining knowledge on abstract image features. The closer the layer is to the bottleneck, the more it deals with higher level features. Since the inception model is already included in the TensorFlow library, we only need the script to retrain the model for our purposes. The TensorFlow For Poets tutorial (https://codelabs.developers.google.com/codelabs/tensorflow-for-poets/#4) provides the completed version of this script, obtainable here:
https://raw.githubusercontent.com/tensorflow/tensorflow/r1.1/tensorflow/examples/image_retraining/retrain.py
With the trainer in hand, we began our data collection process. For each object we wanted to train, we generate the same object in different worlds that guarantee overall different lighting and visibility on the object to diversify training data. We use a simple command
import pyscreenshot as ImageGrab
i=0
while world running:
im = ImageGrab.grab(bbox=(200,200,800,500))
ImageGrab.grab_to_file(('img%d.png' % (i)))
im = Image.open("current_state.png")
rgb_im = im.convert('RGB')
rgb_im.save('current_state.jpg')
i++
to capture a screenshot every second. With this method, we generate roughly 40 object centered/focused images for each object. Afterward, we converted these images to grayscale on the unix command line by running
for i in photosDir/*; do
convert $i -colorspace Gray $i
done
giving us images with less noise.
We started the actual training process by running the retrain.py script as follows
python retrain.py \
--bottleneck_dir=bottlenecks \
--how_many_training_steps=500 \
--model_dir=inception \
--summaries_dir=training_summaries/basic \
--output_graph=retrained_graph.pb \
--output_labels=retrained_labels.txt \
--image_dir=minecraft_photos
The script will proceed to generate bottleneck files, as mentioned above, and begin the training of the final layer. To do so, the trainer runs repeated steps. During each iteration, it randomly chooses 10 images from the training set and retrieves the respective bottlenecks to form a prediction on the final layer. The results will be compared against the true labels of the images. The differences used to update the weight values of the final layer using stochastic gradient descent. Note that we limited the amount of training steps to 500 while a general image classification training on this model will usually run 4000 steps. This is due to the limited size of our training set compared to the amount of images used during normal practices. The recommended number of images for a relatively accurate classifier is 100+. Our collection of 40 images per item meets the moderate requirement for training an admissible A.I. Since increasing training steps will only be beneficial given sufficient amount of training data, we needn’t perform the default of 4000 training steps.
Evaluation
Training Evaluation
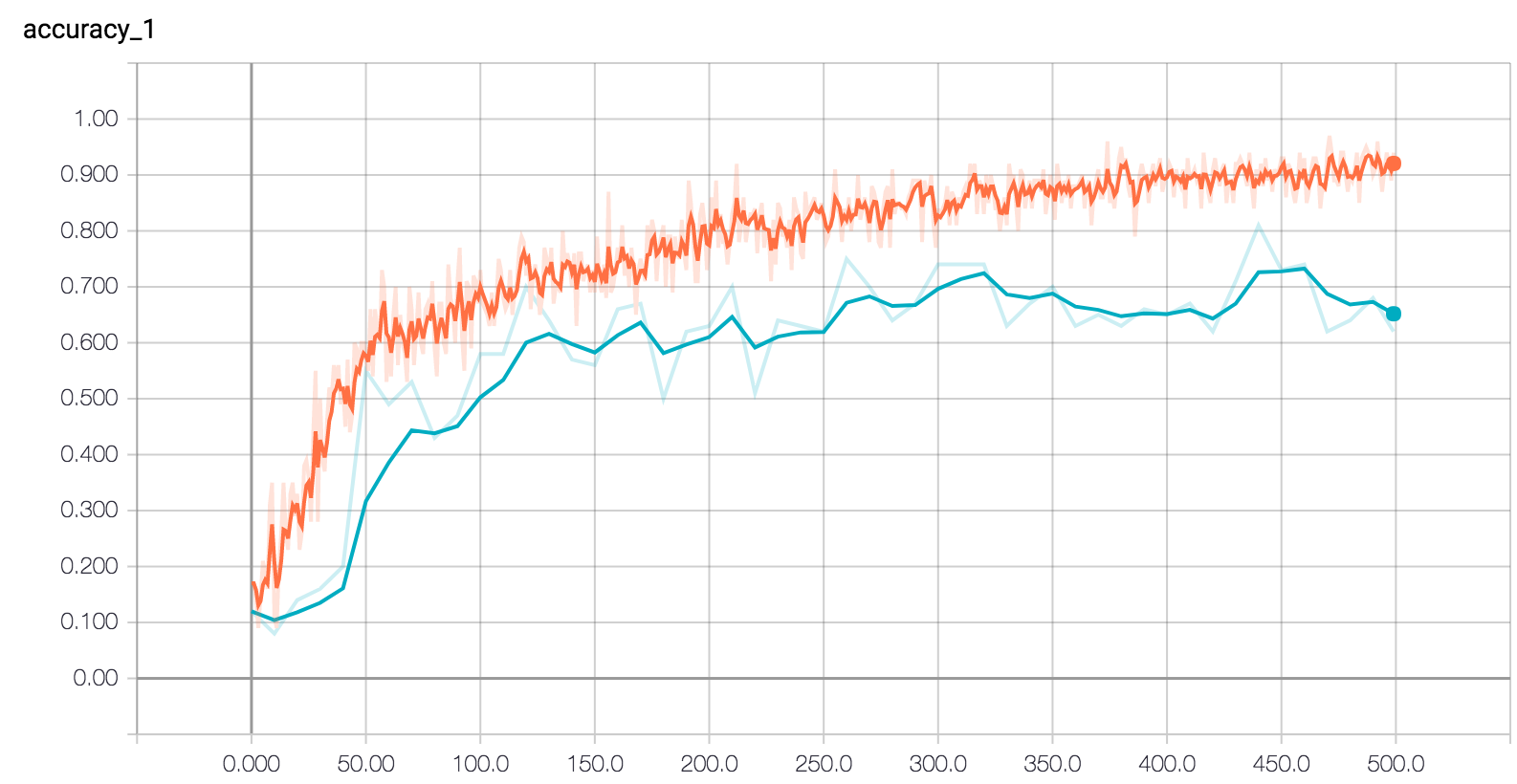
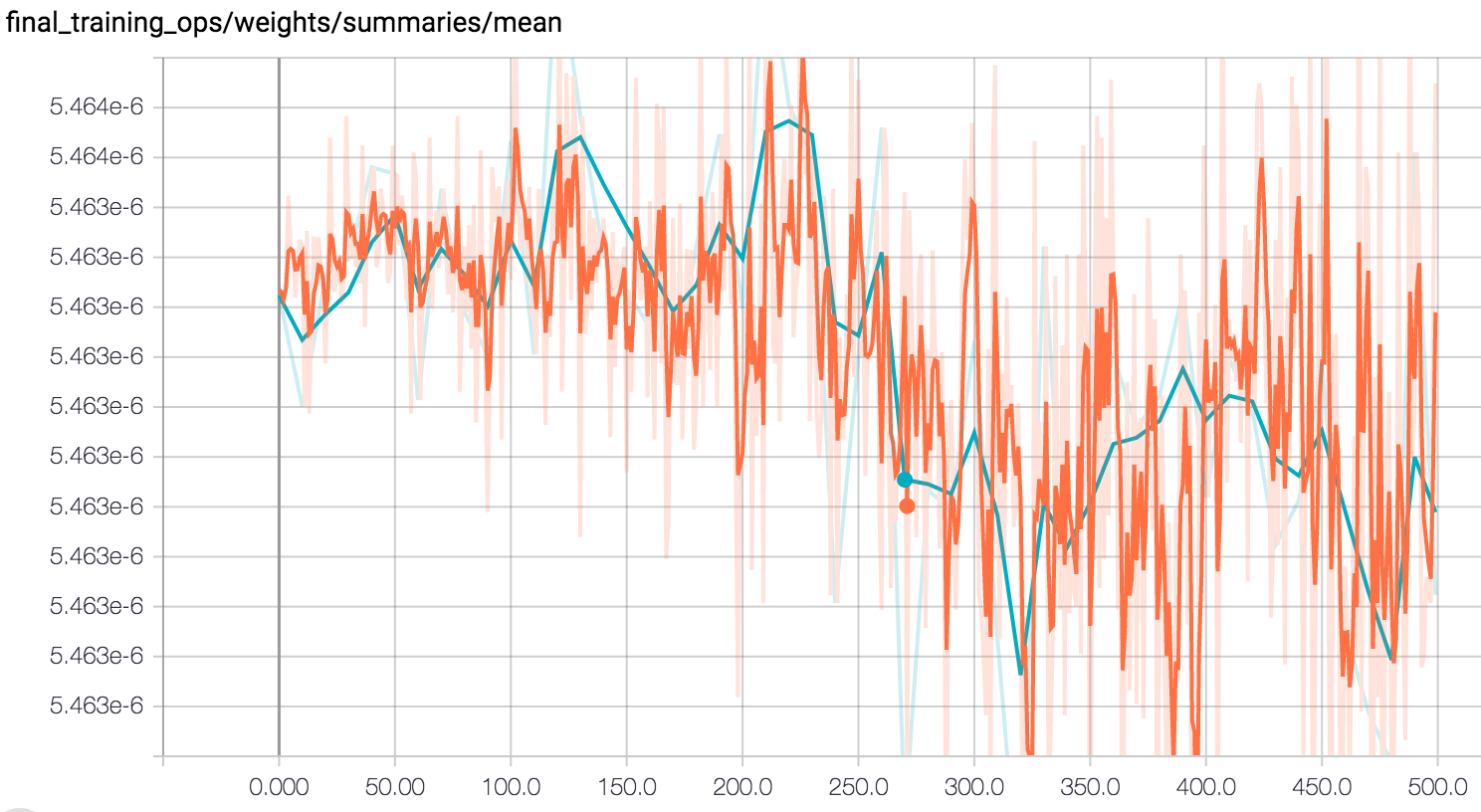
As a step up from our last status report, we increased our class count to 10. We achieved 74% overall training accuracy from tensorflow, which was lowered than the 86% we achieved when training on just 2 objects - something to be expected since we aren’t able to gather the a sufficiently large amount of data for each object class. We can see from the graph that our model reaches maximum performance starting at 350 steps, and at around 500 steps the models starts overfitting as the validation accuracy (as shown by the blue line) starts dropping.
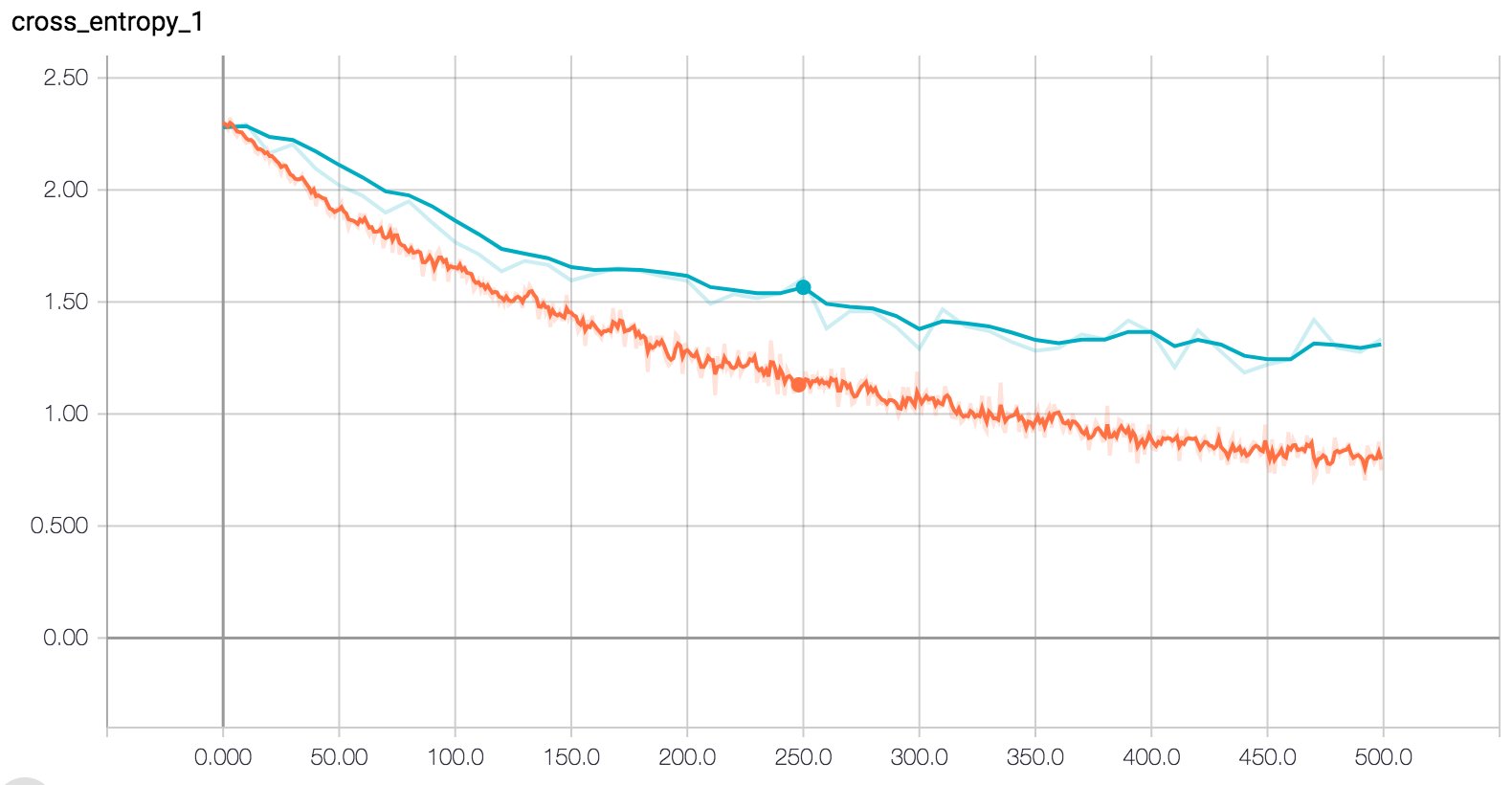
The cross entropy value is another indicator of the performance of our model. As we increase the training steps, we are able to reduce entropy within the classified groups.
Another interesting point to note is the change in the biase values during training. In the graph below, we can see that biase converges to several groups of values, signifying several features picked out by our model for classification.
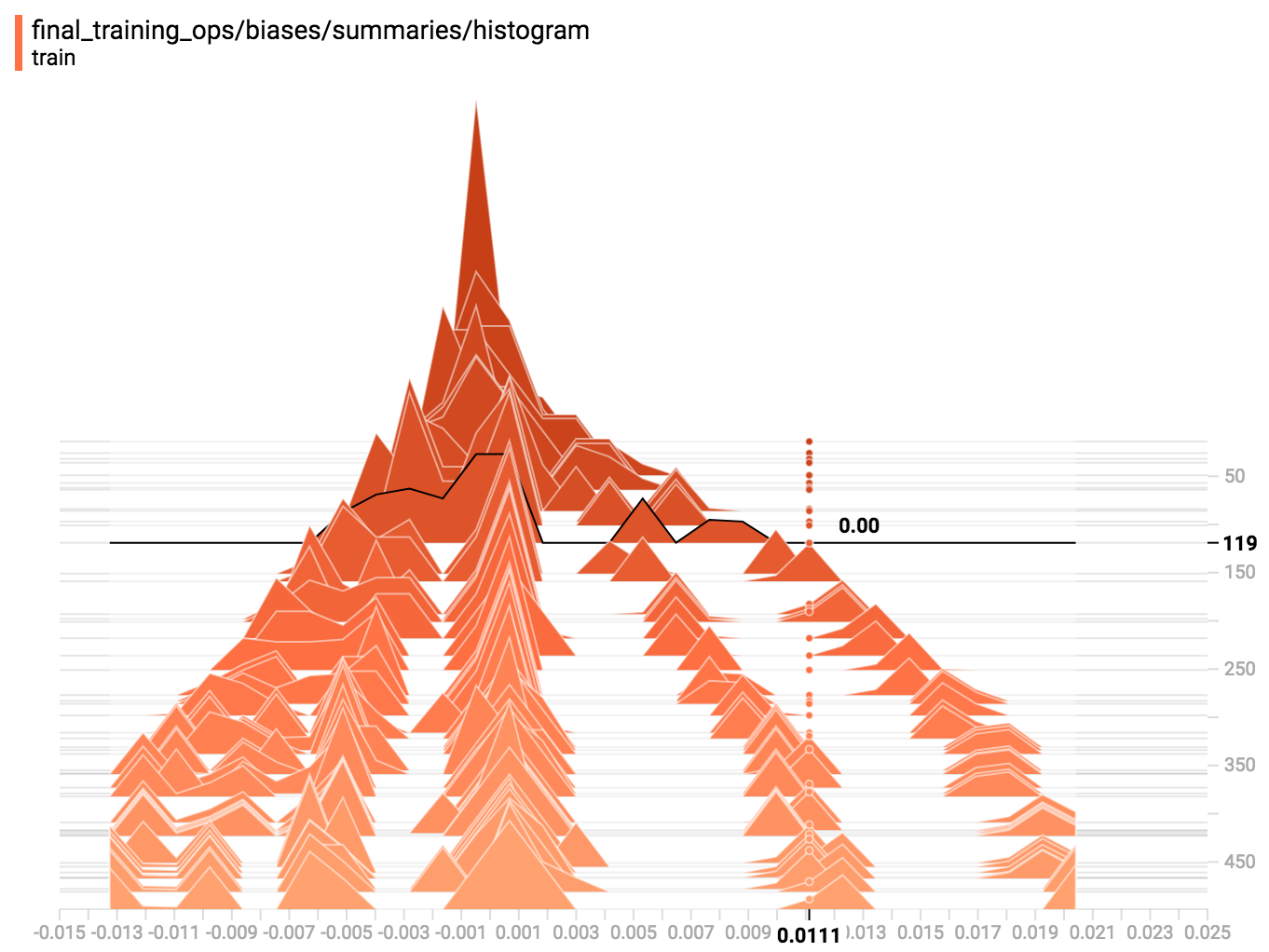
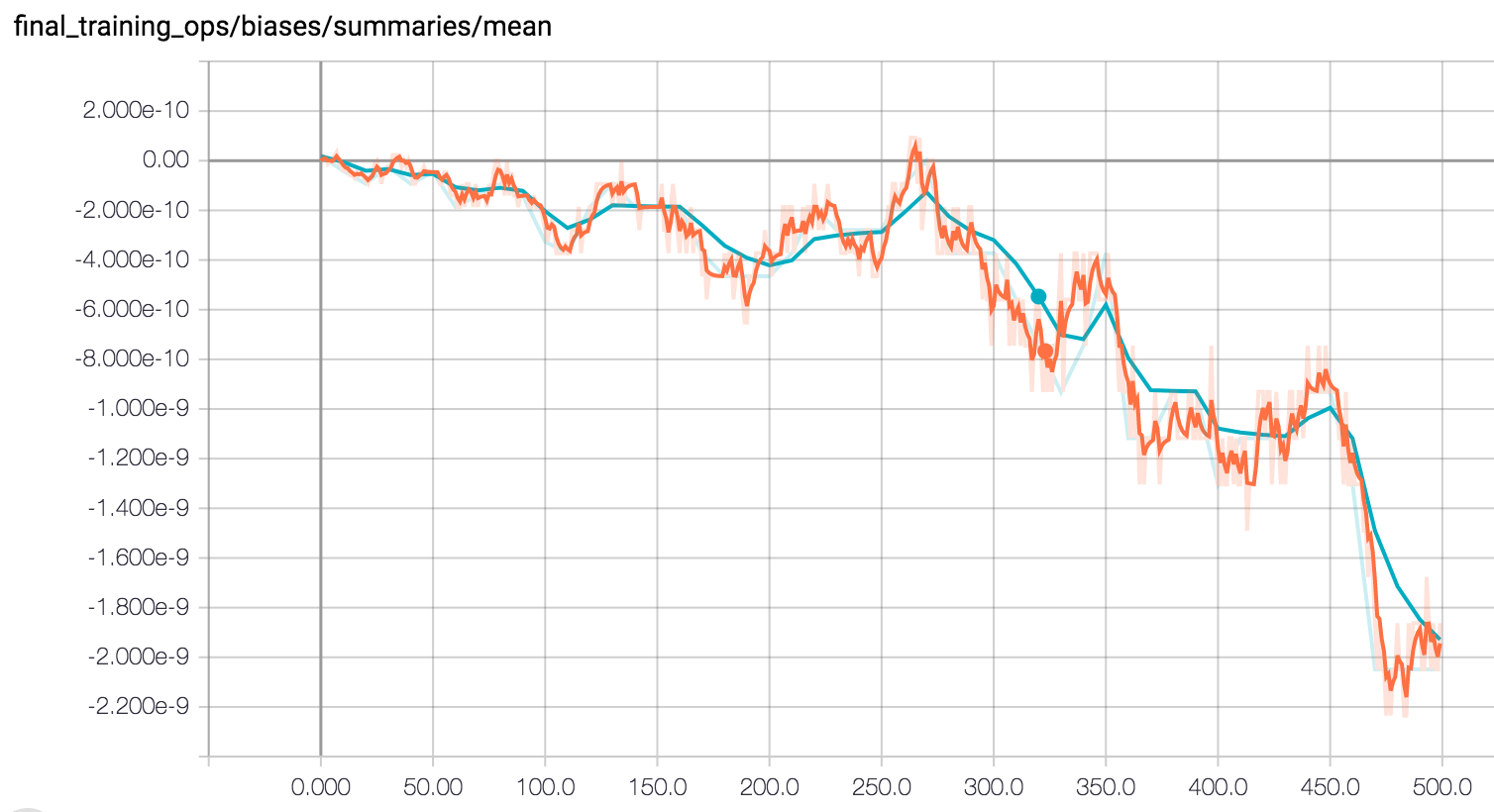
Here is a visualization of the fluctuation of feature parameters as the model is training through gradient descent.
In-game evaluation
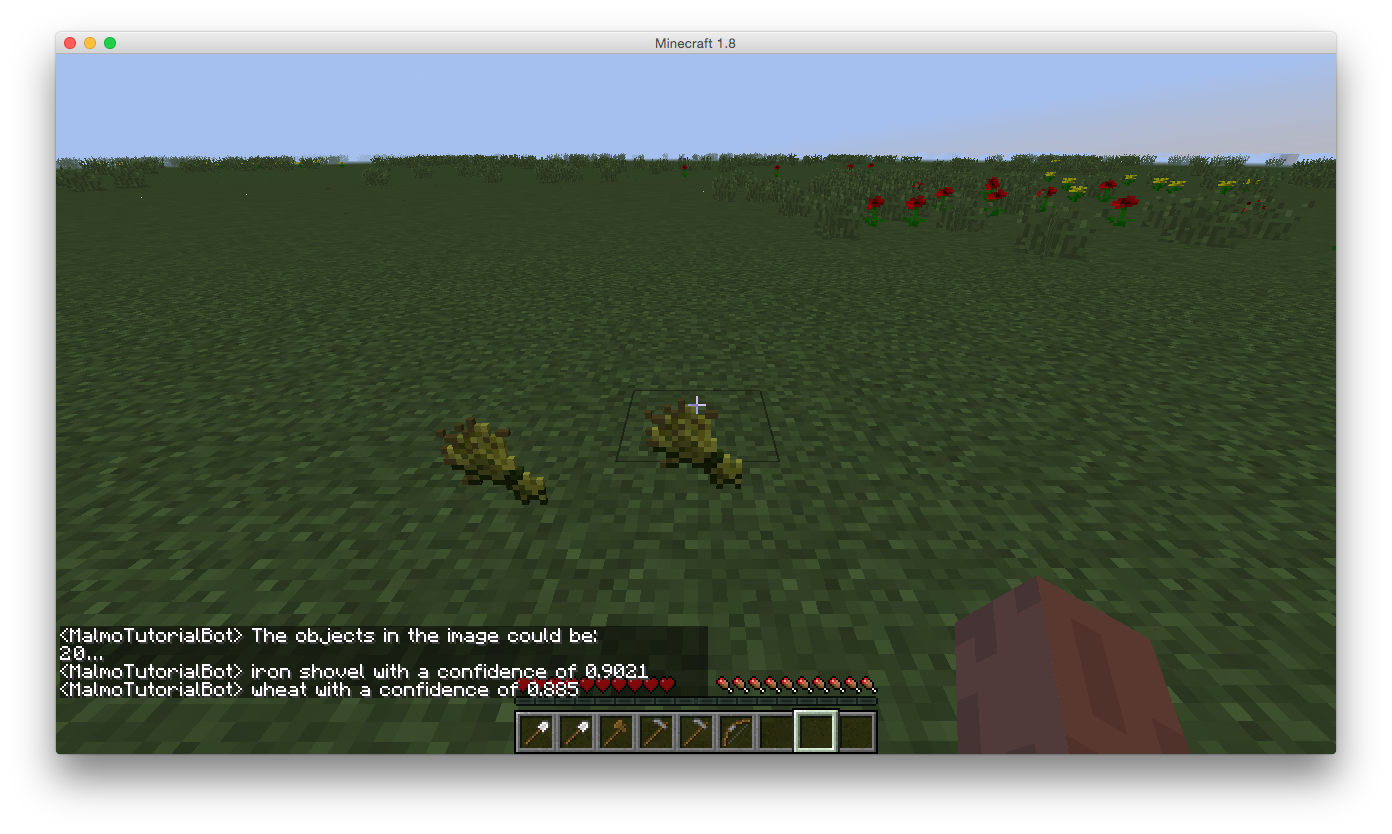
Results
iron shovel (score = 0.9021)
wheat (score = 0.885)
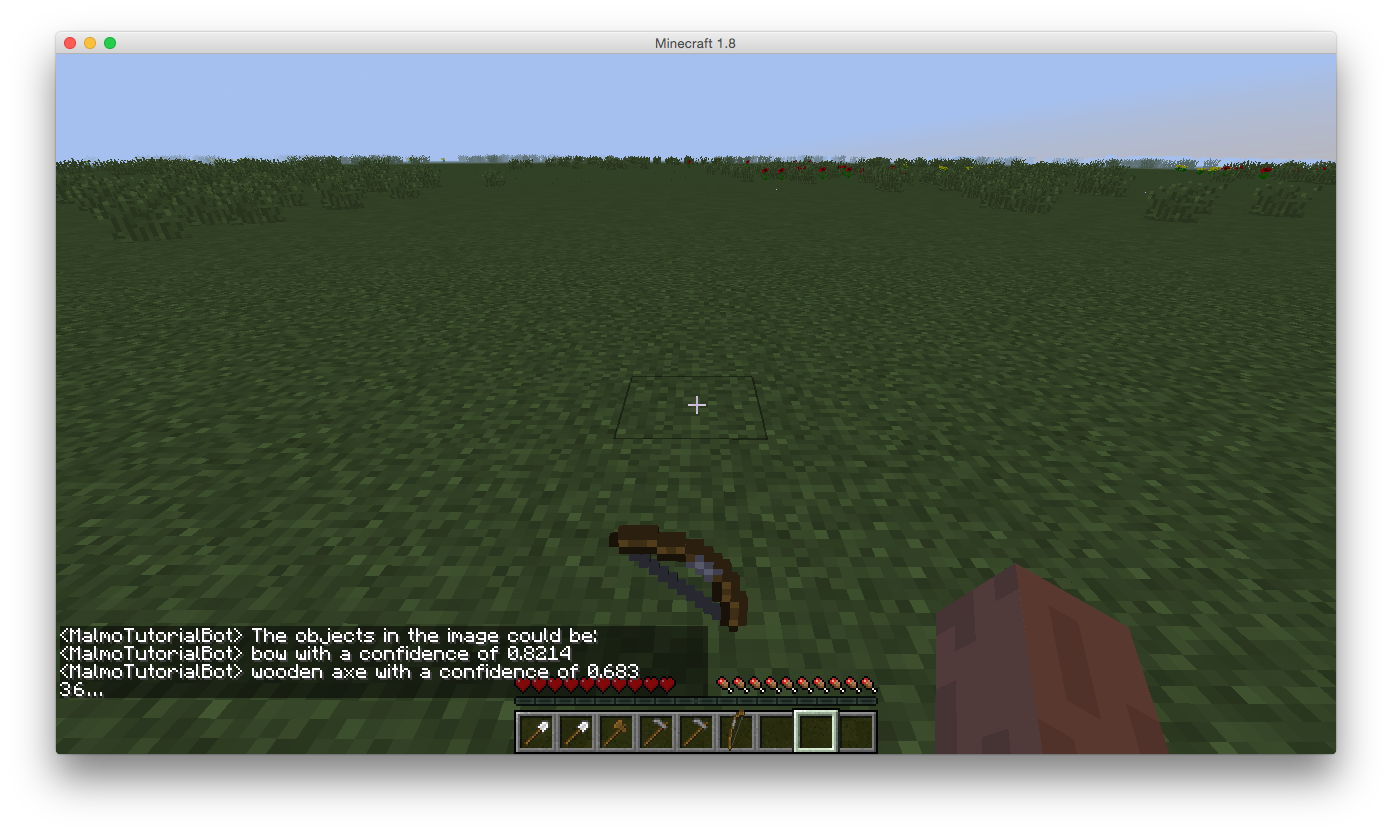
Results
bow (score = 0.8214)
wooden axe (score = 0.683)
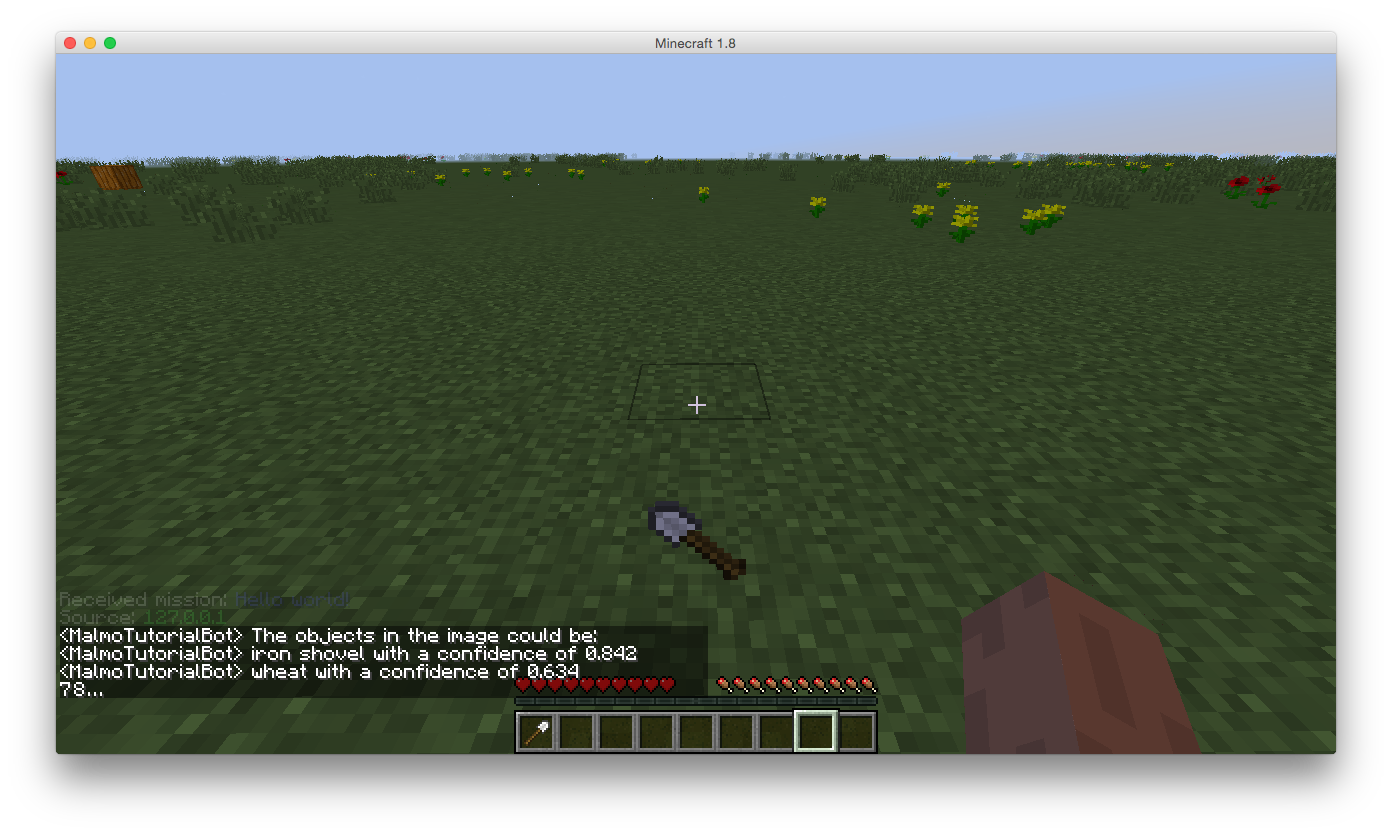
Results
iron shovel (score = 0.842)
wheat (score = 0.634)
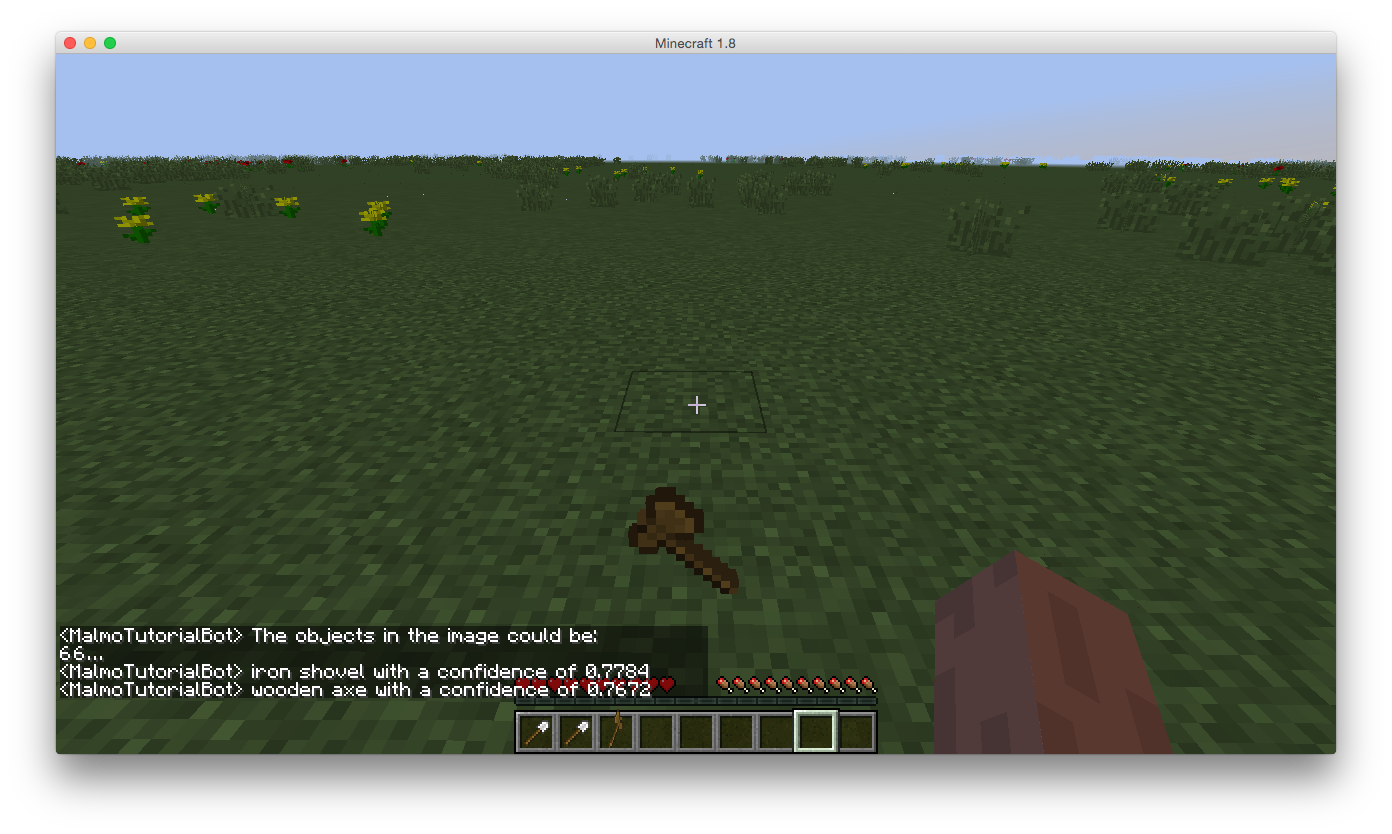
Results
iron shovel (score = 0.7784)
wooden axe (score = 0.7762)
Quantitative Evaluation
For our quantitative evaluation, we used classification rate, which gives us an idea of how many real-time screenshots were accurately classified in relation to the predictions made by our classifier. For example, in the 4 images above, we have output below each image for the different classes that had a high enough confidence level to pass the activation function. Our confidence levels for each class result from TensorFlow’s calculations, which use the softmax function along with the hidden layers’ outputs, weights, activation functions and sigmoid function.
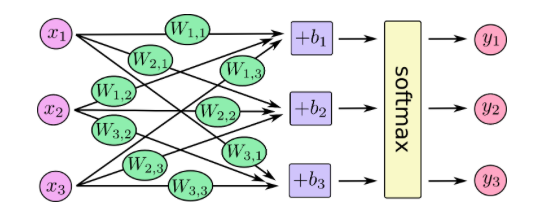
Softmax is used in the final layer of a neural net classifier to compute confidence levels, leading to the classification of the object in the images above as ‘iron shovel’ since the confidence returned in each run is above 0.60. All four of the images did activate the correct output class, but some also activated other output class neurons with even higher confidence levels.
Shovel: 0.33
Bow: 1.0
Wooden Axe: 1.0
Wheat: 0.5
Overall Classifier: 0.57
This was on images that were highly varied and had quite a bit of noise in them. To deal with such noise we plan to optimize our in game screenshots: implement a co-existing object identifier algorithm along with our classification algorithm. Together, these algorithms create true vision. Furthermore, we plan to increase our data set once again with more items each with 200 pictures. Images will mainly be varied by occluding objects. We hope to achieve better accuracy this way and bump our accuracy up to 75%.
Further information and visualization of the softmax equation used in TensorFlow (taken from TensorFlow Documentation):


Qualitative Evaluation
For our qualitative evaluation, we wanted to make sure that similar items could be differentiated from each other. Therefore, we chose to train our subset of items as: (similar items are adjacent to each other)
golden_axe wooden_axe
iron_shovel stone_hoe
wheat (Commonly appears bc classifier is confusing it with grass)
leather_boots bowl
bow
diamond_sword
As seen in the images above, we were able to avoid some situations in which items could be confused: a stone hue and an iron shovel. Other than this we were able to test our AI in various environments. No matter snow, rain or clear weather, our AI was accurately able to recognize the items. Occluding objects in the environment such as boxes, grass, trees and flowers do negatively affect our algorithm, depending on how much of the object is hidden. If at least 60% of the object is visible our AI can guess the object within its top three choices. These variations helped us qualitatively evaluate our project. For future iterations, we would like to add more angles, as we only tested on straight point-of-view angles in the above images.
References
Project Malmo as our playground
TensorFlow as our Computer Vision API for training a classifier